In short: Bulk-exports the first Google Search results for a provided set of search queries.
Click to view the example results file for a better idea of the output.
Video tutorial
Watch how I quickly use this tool as a company name to website finder:
Why scrape Google’s first results
This fast and simple bot can be used for multiple business-related purposes. It can help you:
- Get website URL from company name in bulk
- Get to know your competition
- Analyze your competitors’ meta titles and meta descriptions
- Improve your own meta tags
- Quickly extract domains from longer site URLs
- And many more!
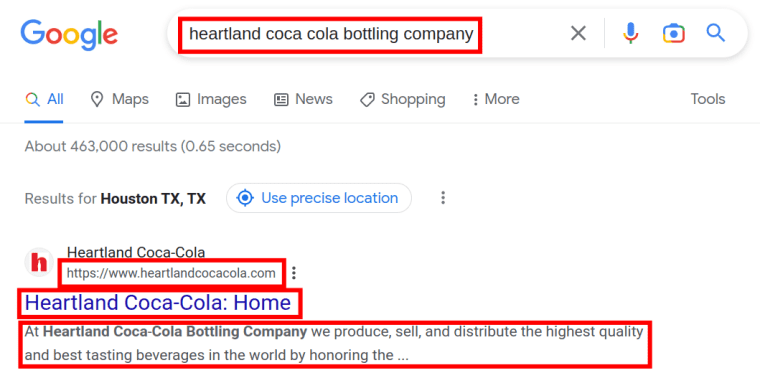
The Google First Result Finder can easily grab the following details:
- Query
- URL
- Domain
- Title
- Description
How to extract the first Google Search results in bulk?
- Sign up on Botster
- Go to the bot's start page
- Set your location
- Select the language
- Adjust custom settings
- Enter your keywords. Each query must go on a new line
- Click the "Start this bot" button
That's it – the Google First Result Finder has started working!
Software walkthrough
1. Open the Launch bot form.
Click on the "Start bot" button on the right-hand side of this page to open the spider's form:
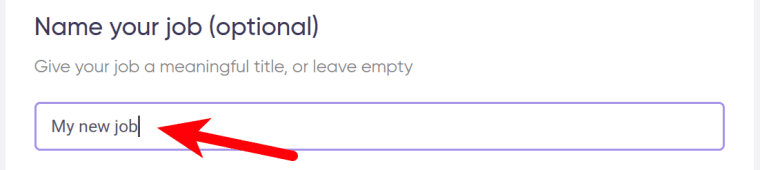
 2. Enter the details.
2. Enter the details.
Give your "Job" a meaningful title, and optionally specify (or create) a project folder:
 3. Enter your location.
3. Enter your location.
 4. Select the target language.
4. Select the target language.
 5. Specify the device (desktop or mobile).
5. Specify the device (desktop or mobile).
 6. Select the operating system.
6. Select the operating system.
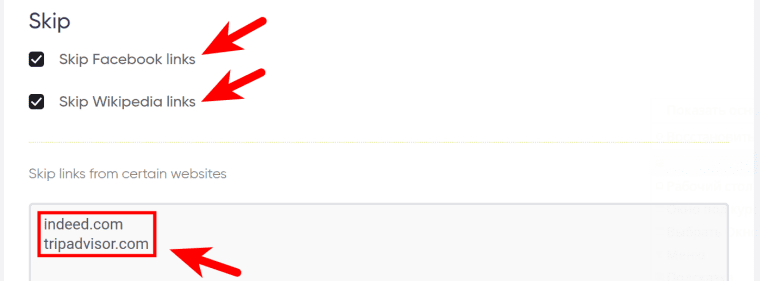
 7. Specify the websites to skip.
7. Specify the websites to skip.
Tick and/or enter the websites that the bot isn’t supposed to check.
⚠️ Each site must go on a new line:
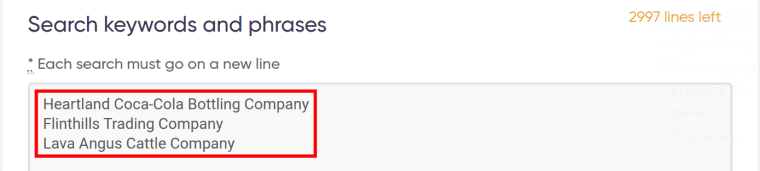
 8. Enter your keywords.
8. Enter your keywords.
⚠️ Each query must go on a new line:
 9. Specify time settings.
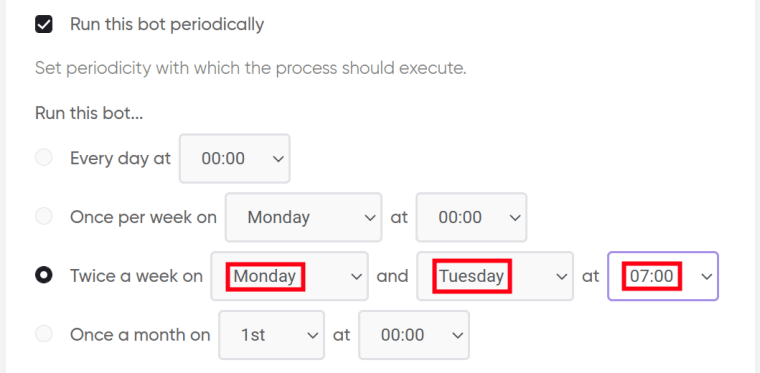
9. Specify time settings.
Tick the checkbox if you want the Google First Result Finder to scrape the first results from Google Search on a regular basis:
 Once you’ve ticked the checkbox, the available options will appear. You can set the bot to run:
Once you’ve ticked the checkbox, the available options will appear. You can set the bot to run:
- every day
- twice a day
- once a week
- twice a week
- once a month
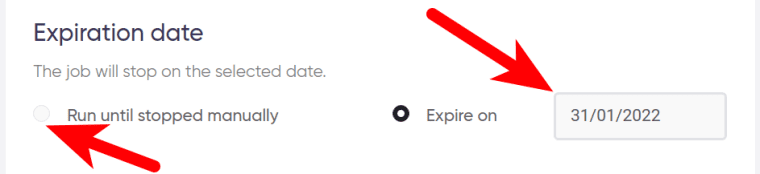
 If no longer needed, the Google First Result Finder can be stopped either manually or at a certain date specified in advance:
If no longer needed, the Google First Result Finder can be stopped either manually or at a certain date specified in advance:
 Tick ‘Deliver new items only’ if you want the Google First Result Finder to send you updates only:
Tick ‘Deliver new items only’ if you want the Google First Result Finder to send you updates only:
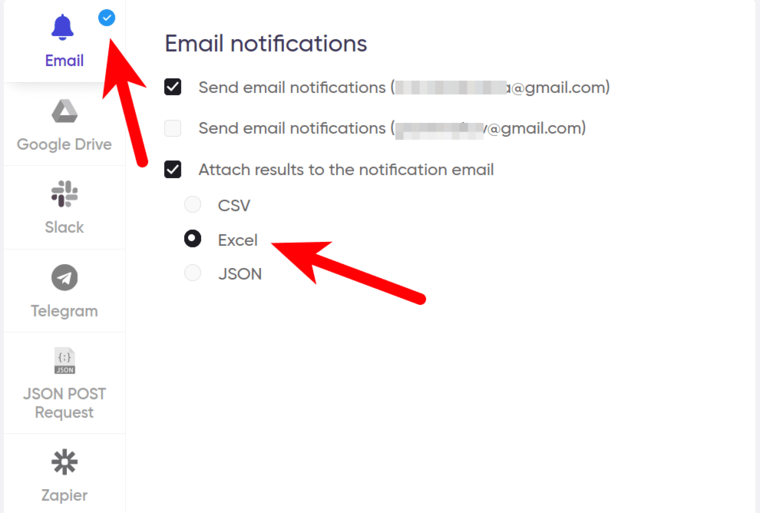
 10. Set up notifications.
10. Set up notifications.
Specify if you would like to receive a notification when the grabber completes the crawl:
 11. Start the bot!
11. Start the bot!
Click the "Start this bot" button on the right-hand side:
 That's it! You will be taken to your "Jobs" section. The software is now working and will notify you once it's done.
That's it! You will be taken to your "Jobs" section. The software is now working and will notify you once it's done.
Data output
After the bot completes the job you can download your data as an Excel (XLSX), CSV or JSON file.