In short: This online tool will extract contact information from a list of websites.
Click to view the example results file for a better idea of the output.
More examples:
⚠️ To export contacts from directories and listings (business directories, property listings, event lists, etc.), use the No-Code Bot Builder. ⚠️
⚠️ The bot works smoothly with small to mid-sized websites, however, if you are going for larger sites with enabled bot/spam protection, the bot won't work at all. ⚠️
How to scrape phones and emails from websites? Video guide
Watch me quickly walk you through the email and phone number crawler bot's setup:
And this is a more detailed bot guide:
A fast and simple email lead extracting software, this bot can be used for multiple purposes.
You can easily grab the following contact details:
- Emails
- Cell and work phone numbers, including potential phone numbers
- Links to contact pages
- Links to social networks
- Links to messengers
How to scrape contact details from websites?
- Sign up on Botster
- Go to the bot's start page
- Enter the links to websites. Each URL must go on a new line
- Select the contact types you would like to scrape (phones, emails, social network links, etc.)
- Select the number of pages to visit (per site)
- Adjust custom settings
- Click the "Start this bot" button.
That's it – the email and phone number extractor process has started!
Troubleshooting
Captcha and bot protection
It is known that the phone grabber bot won't be able to access websites in case they are using bot protection solutions such as CloudFlare, etc.
AJAX
This email harvesting program is likely to have trouble parsing complex AJAX-heavy documents.
Software walkthrough
1. Open the Launch bot form
Click on the "Start bot" button on the right-hand side of this page to open the spider's form:

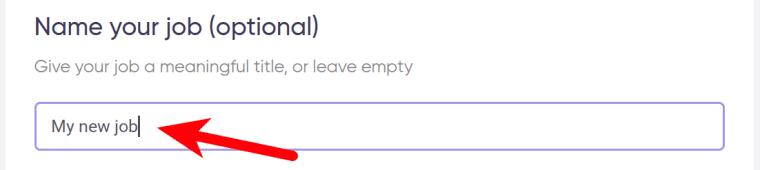
2. Enter the details
Give your "Job" a meaningful title, and optionally specify (or create) a project folder:
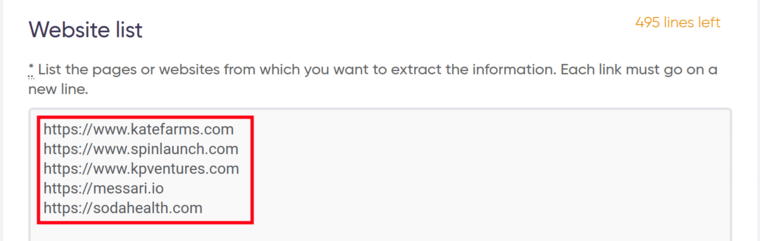
3. Enter the websites.
Insert a list of URLs that we will be scraping contact details from.
Each link must go on a new line:
4. Select the contact type(s).
Tick the contact types (emails, phone numbers, links to social networks, etc.) that you would like the bot to export:

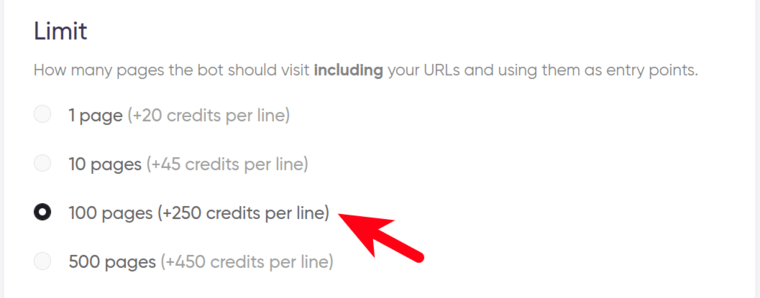
5. Set the limit.
Select the number of pages to visit (per site):
6. Enter allowed URL strings.
Optionally, you can filter out which pages the bot needs to scrape by specifying parts of URLs.
For example, if you would like the bot to extract data from pages that have /products/ in their URLs only, this is the input where you can indicate exactly that, and the bot will ignore the rest.
Each string must go on a new line:
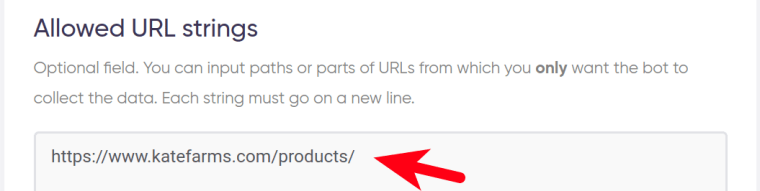
7. Enter ignored URLs.
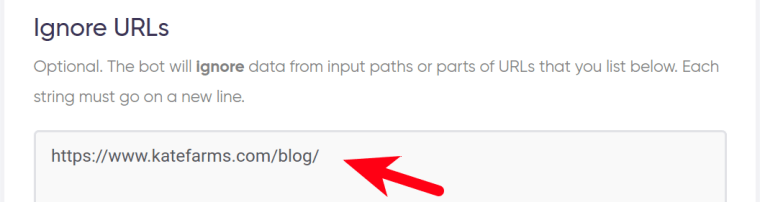
Similarly, you can tell the bot which pages it needs to ignore by indicating parts of such URLs. For example, if you don't need any information extracted from a certain group of pages.
This field is also optional.
Each string must go on a new line:
8. Specify if selenium should be used.
Tick the checkbox if you would like to extract more data from JS websites. This option increases the time needed and the price of the job:

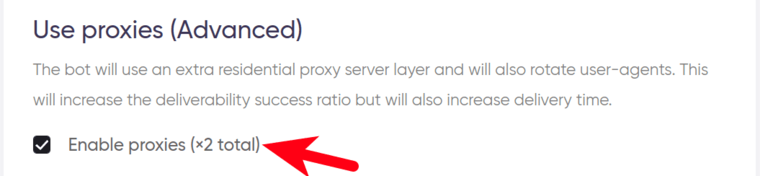
9. Specify if an extra proxy server should be used.
Tick the checkbox if you would like to use a residential proxy layer. This works great agains tough protection mechanisms. This option increases the time needed and the price of the job:
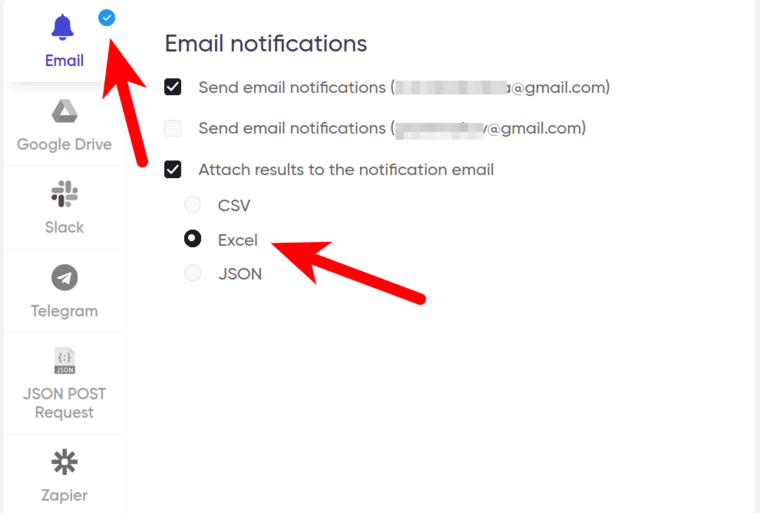
10. Set up notifications.
Specify if you would like to receive a notification when the grabber completes the crawl:
11. Start the bot!
Click the "Start this bot" button on the right-hand side:

That's it! You will be taken to your "Jobs" section. The software is now working and will notify you once it's done.
Data output
After the bot completes the job you can download your data as an Excel (XLSX), CSV or JSON file.